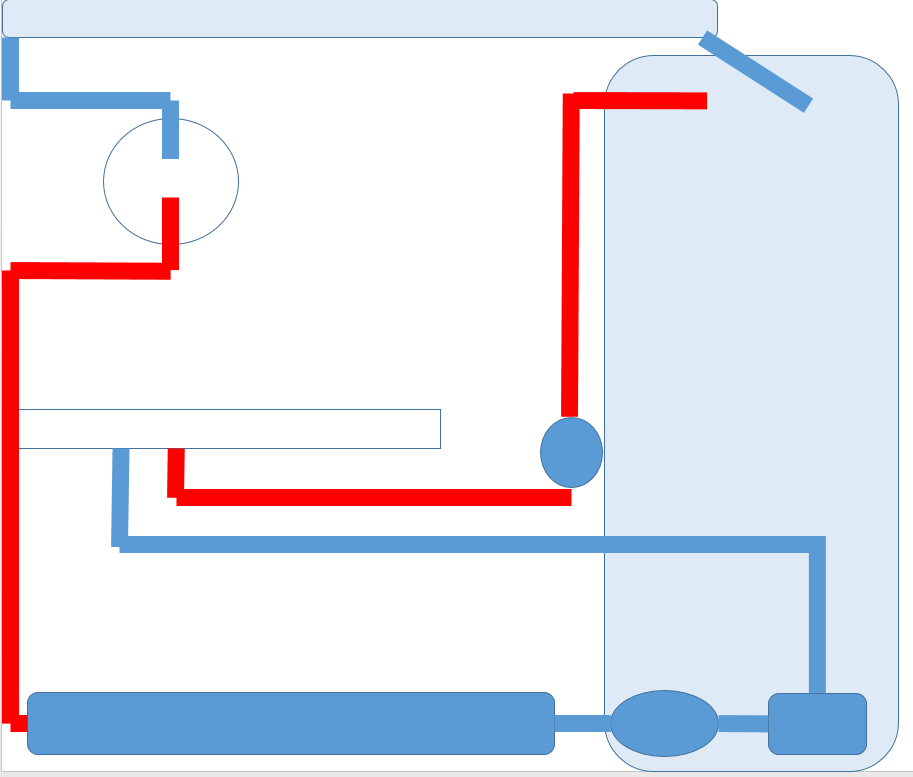
주요 구성
CPU 워터블록 1개,
VGA 워터블록 1개,
라디에이터 360 2개,
유량 센서 1개,
디스플레이 온도 센서 1개,
온도 센서 2개,
펌프 1개,
300mm 펌프 1개
리안리 PC-O9WX에 배치할 수로 구성,
공간적인 문제, 심미적인 문제로 물통을 눞여서 사용할 계획
이제 나이 먹어 강제로 4.0 버전업됨, 일인개발자임, 파키스탄식 코딩.. 오래된 코드도 다시 쓴다.
주요 구성
CPU 워터블록 1개,
VGA 워터블록 1개,
라디에이터 360 2개,
유량 센서 1개,
디스플레이 온도 센서 1개,
온도 센서 2개,
펌프 1개,
300mm 펌프 1개
리안리 PC-O9WX에 배치할 수로 구성,
공간적인 문제, 심미적인 문제로 물통을 눞여서 사용할 계획
드뎌 2주만에 주문 시킨 메모리 도착
하지만.. 장착 할 PC가 현재 없다는게 함정

겉 포장은 대 놓고 라이젠 호환이라 써 있는데 왠지 정상 클럭으로 인식될거 같은 기대감이 생긴다.

방열판 모양은 왠지 커세어 VENGEANCE시리즈 모양 비스무리 하고 LED 기능은 없는거 같다..

최근 나온 G.Skill Tridentz RGB 모양이였으면 좋았을텐데..
| 타입 | DDR4 |
| 클럭 | PC4-25600 (3200Mhz) |
| 용량 | 8GB * 2ea |
| 램타이밍 | 14-14-14-34 |
| 전압 | 1.35v |
실제 작동 후기는 월말이나 되서 쓸거 같다.. 후아..

출근길 광명시청 주변도로 지나던 도중 검은색 연기가 피어 오르길래 보니까 불이 크게 났..

다행히 다친 사람은 없는듯..
가끔 개발 하다 보면 파일 입출력시 동적으로 인코딩 처리를 해야할 경우가 있다.
아래 클래스를 사용하여 이용할 경우 상당히 유용하게 쓰일 수 있다.
// -----------------------------------------------------------------------
// <copyright file="TextEncodingDetect.cs" company="AutoIt Consulting Ltd">
// Copyright (c)2014 AutoIt Consulting Ltd. All rights reserved.
// </copyright>
// -----------------------------------------------------------------------
///////////////////////////////////////////////////////////////////////////////
//
// Copyright(c) 2014, Jonathan Bennett & AutoIt Consulting Ltd
// All rights reserved.
// http://www.autoitconsulting.com
//
// Redistribution and use in source and binary forms, with or without
// modification, are permitted provided that the following conditions are met :
// *Redistributions of source code must retain the above copyright
// notice, this list of conditions and the following disclaimer.
// * Redistributions in binary form must reproduce the above copyright
// notice, this list of conditions and the following disclaimer in the
// documentation and / or other materials provided with the distribution.
//
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
// ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
// WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
// DISCLAIMED.IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
// ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
// (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
// LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
// ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
// SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
//
///////////////////////////////////////////////////////////////////////////////
public class TextEncodingDetect
{
#region Fields
private readonly byte[] utf16LEBOM = { 0xFF, 0xFE };
private readonly byte[] utf16BEBOM = { 0xFE, 0xFF };
private readonly byte[] utf8BOM = { 0xEF, 0xBB, 0xBF };
private bool nullSuggestsBinary = true;
private double utf16ExpectedNullPercent = 70;
private double utf16UnexpectedNullPercent = 10;
#endregion
#region Enums
public enum Encoding
{
None, // Unknown or binary
ANSI, // 0-255
ASCII, // 0-127
UTF8_BOM, // UTF8 with BOM
UTF8_NOBOM, // UTF8 without BOM
UTF16_LE_BOM, // UTF16 LE with BOM
UTF16_LE_NOBOM, // UTF16 LE without BOM
UTF16_BE_BOM, // UTF16-BE with BOM
UTF16_BE_NOBOM // UTF16-BE without BOM
}
#endregion
#region Properties
public bool NullSuggestsBinary
{
set
{
this.nullSuggestsBinary = value;
}
}
public double Utf16ExpectedNullPercent
{
set
{
if (value > 0 && value < 100)
{
this.utf16ExpectedNullPercent = value;
}
}
}
public double Utf16UnexpectedNullPercent
{
set
{
if (value > 0 && value < 100)
{
this.utf16UnexpectedNullPercent = value;
}
}
}
#endregion
public static int GetBOMLengthFromEncodingMode(Encoding encoding)
{
int length = 0;
if (encoding == Encoding.UTF16_BE_BOM || encoding == Encoding.UTF16_LE_BOM)
{
length = 2;
}
else if (encoding == Encoding.UTF8_BOM)
{
length = 3;
}
return length;
}
public Encoding CheckBOM(byte[] buffer, int size)
{
// Check for BOM
if (size >= 2 && buffer[0] == this.utf16LEBOM[0] && buffer[1] == this.utf16LEBOM[1])
{
return Encoding.UTF16_LE_BOM;
}
else if (size >= 2 && buffer[0] == this.utf16BEBOM[0] && buffer[1] == this.utf16BEBOM[1])
{
return Encoding.UTF16_BE_BOM;
}
else if (size >= 3 && buffer[0] == this.utf8BOM[0] && buffer[1] == this.utf8BOM[1] && buffer[2] == this.utf8BOM[2])
{
return Encoding.UTF8_BOM;
}
else
{
return Encoding.None;
}
}
public Encoding DetectEncoding(byte[] buffer, int size)
{
// First check if we have a BOM and return that if so
Encoding encoding = this.CheckBOM(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// Now check for valid UTF8
encoding = this.CheckUTF8(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// Now try UTF16
encoding = this.CheckUTF16NewlineChars(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
encoding = this.CheckUTF16ASCII(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// ANSI or None (binary) then
if (!this.DoesContainNulls(buffer, size))
{
return Encoding.ANSI;
}
else
{
// Found a null, return based on the preference in null_suggests_binary_
if (this.nullSuggestsBinary)
{
return Encoding.None;
}
else
{
return Encoding.ANSI;
}
}
}
///////////////////////////////////////////////////////////////////////////////
// Checks if a buffer contains valid utf8. Returns:
// None - not valid utf8
// UTF8_NOBOM - valid utf8 encodings and multibyte sequences
// ASCII - Only data in the 0-127 range.
///////////////////////////////////////////////////////////////////////////////
private Encoding CheckUTF8(byte[] buffer, int size)
{
// UTF8 Valid sequences
// 0xxxxxxx ASCII
// 110xxxxx 10xxxxxx 2-byte
// 1110xxxx 10xxxxxx 10xxxxxx 3-byte
// 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 4-byte
//
// Width in UTF8
// Decimal Width
// 0-127 1 byte
// 194-223 2 bytes
// 224-239 3 bytes
// 240-244 4 bytes
//
// Subsequent chars are in the range 128-191
bool only_saw_ascii_range = true;
uint pos = 0;
int more_chars;
while (pos < size)
{
byte ch = buffer[pos++];
if (ch == 0 && this.nullSuggestsBinary)
{
return Encoding.None;
}
else if (ch <= 127)
{
// 1 byte
more_chars = 0;
}
else if (ch >= 194 && ch <= 223)
{
// 2 Byte
more_chars = 1;
}
else if (ch >= 224 && ch <= 239)
{
// 3 Byte
more_chars = 2;
}
else if (ch >= 240 && ch <= 244)
{
// 4 Byte
more_chars = 3;
}
else
{
return Encoding.None; // Not utf8
}
// Check secondary chars are in range if we are expecting any
while (more_chars > 0 && pos < size)
{
only_saw_ascii_range = false; // Seen non-ascii chars now
ch = buffer[pos++];
if (ch < 128 || ch > 191)
{
return Encoding.None; // Not utf8
}
--more_chars;
}
}
// If we get to here then only valid UTF-8 sequences have been processed
// If we only saw chars in the range 0-127 then we can't assume UTF8 (the caller will need to decide)
if (only_saw_ascii_range)
{
return Encoding.ASCII;
}
else
{
return Encoding.UTF8_NOBOM;
}
}
///////////////////////////////////////////////////////////////////////////////
// Checks if a buffer contains text that looks like utf16 by scanning for
// newline chars that would be present even in non-english text.
// Returns:
// None - not valid utf16
// UTF16_LE_NOBOM - looks like utf16 le
// UTF16_BE_NOBOM - looks like utf16 be
///////////////////////////////////////////////////////////////////////////////
private Encoding CheckUTF16NewlineChars(byte[] buffer, int size)
{
if (size < 2)
{
return Encoding.None;
}
// Reduce size by 1 so we don't need to worry about bounds checking for pairs of bytes
size--;
int le_control_chars = 0;
int be_control_chars = 0;
byte ch1, ch2;
uint pos = 0;
while (pos < size)
{
ch1 = buffer[pos++];
ch2 = buffer[pos++];
if (ch1 == 0)
{
if (ch2 == 0x0a || ch2 == 0x0d)
{
++be_control_chars;
}
}
else if (ch2 == 0)
{
if (ch1 == 0x0a || ch1 == 0x0d)
{
++le_control_chars;
}
}
// If we are getting both LE and BE control chars then this file is not utf16
if (le_control_chars > 0 && be_control_chars > 0)
{
return Encoding.None;
}
}
if (le_control_chars > 0)
{
return Encoding.UTF16_LE_NOBOM;
}
else if (be_control_chars > 0)
{
return Encoding.UTF16_BE_NOBOM;
}
else
{
return Encoding.None;
}
}
///////////////////////////////////////////////////////////////////////////////
// Checks if a buffer contains text that looks like utf16. This is done based
// the use of nulls which in ASCII/script like text can be useful to identify.
// Returns:
// None - not valid utf16
// UTF16_LE_NOBOM - looks like utf16 le
// UTF16_BE_NOBOM - looks like utf16 be
///////////////////////////////////////////////////////////////////////////////
private Encoding CheckUTF16ASCII(byte[] buffer, int size)
{
int num_odd_nulls = 0;
int num_even_nulls = 0;
// Get even nulls
uint pos = 0;
while (pos < size)
{
if (buffer[pos] == 0)
{
num_even_nulls++;
}
pos += 2;
}
// Get odd nulls
pos = 1;
while (pos < size)
{
if (buffer[pos] == 0)
{
num_odd_nulls++;
}
pos += 2;
}
double even_null_threshold = (num_even_nulls * 2.0) / size;
double odd_null_threshold = (num_odd_nulls * 2.0) / size;
double expected_null_threshold = this.utf16ExpectedNullPercent / 100.0;
double unexpected_null_threshold = this.utf16UnexpectedNullPercent / 100.0;
// Lots of odd nulls, low number of even nulls
if (even_null_threshold < unexpected_null_threshold && odd_null_threshold > expected_null_threshold)
{
return Encoding.UTF16_LE_NOBOM;
}
// Lots of even nulls, low number of odd nulls
if (odd_null_threshold < unexpected_null_threshold && even_null_threshold > expected_null_threshold)
{
return Encoding.UTF16_BE_NOBOM;
}
// Don't know
return Encoding.None;
}
///////////////////////////////////////////////////////////////////////////////
// Checks if a buffer contains any nulls. Used to check for binary vs text data.
///////////////////////////////////////////////////////////////////////////////
private bool DoesContainNulls(byte[] buffer, int size)
{
uint pos = 0;
while (pos < size)
{
if (buffer[pos++] == 0)
{
return true;
}
}
return false;
}
}
아래는 활용 방법 예시
public static Stream ConvertEncodingData(string filePath)
{
Stream result = null;
byte[] buffer = System.IO.File.ReadAllBytes(filePath);
// Detact Encoding
var textDetect = new Text.TextEncodingDetect();
Text.TextEncodingDetect.Encoding encoding = textDetect.DetectEncoding(buffer, buffer.Length);
Encoding findEncoding = Encoding.Default;
switch (encoding)
{
case Text.TextEncodingDetect.Encoding.ASCII:
findEncoding = Encoding.ASCII;
break;
case Text.TextEncodingDetect.Encoding.UTF8_BOM:
case Text.TextEncodingDetect.Encoding.UTF8_NOBOM:
findEncoding = Encoding.UTF8;
break;
case Text.TextEncodingDetect.Encoding.UTF16_LE_BOM:
case Text.TextEncodingDetect.Encoding.UTF16_LE_NOBOM:
findEncoding = Encoding.Unicode;
break;
case Text.TextEncodingDetect.Encoding.UTF16_BE_BOM:
case Text.TextEncodingDetect.Encoding.UTF16_BE_NOBOM:
findEncoding = Encoding.BigEndianUnicode;
break;
case Text.TextEncodingDetect.Encoding.None:
default:
case Text.TextEncodingDetect.Encoding.ANSI:
findEncoding = Encoding.Default;
break;
}
// Make Stream
using (StreamReader reader = new StreamReader(filePath, findEncoding))
{
if (findEncoding == Encoding.UTF8)
{
byte[] data = reader.CurrentEncoding.GetBytes(reader.ReadToEnd());
result = new MemoryStream(data);
}
else
{
byte[] strByte = reader.CurrentEncoding.GetBytes(reader.ReadToEnd());
byte[] utf8Byte = Encoding.Convert(reader.CurrentEncoding, Encoding.UTF8, strByte);
result = new MemoryStream(utf8Byte);
}
reader.Close();
}
return result;
}
출저 : http://www.autoitconsulting.com (TextEncodingDetect class)

라이젠 보드 문제인지 칩셋 문제인지 모르겠는데, 고성능 메모리에서 호환성이 문제가 많다.
그래서 눈팅 하다 보니 실제 고 클럭메모리를 다운그레이드해서 쓰는 사람들이 많이 있던데, 왠지 그러기는 찝찝하고 해서 사려는 보드의 QVL 메모리 목록 보고, 웹도 뒤져보다가 적합한 메모리 발견
G.Skill 사의 F4-3200C14D-16GFX
국내 정식 유통은 되지 않고, 새알(newegg.com)에서 조차 안팔아서 돌고 돌아 쌩뚱 맞기 독일에 컴퓨터 유통점에서 구입하게 됬다.
번역기 돌려가며 구입하는데도 한참 걸렸는데, 오늘 통관되었다는 문제 받았다.
곧 이 놈을 만나볼텐데.. 과연 실제 3200Mhz 풀뱅 32G 작동 할 것인가가 문제다.
총 구입 비용은
메모리 가격 : 201.59 EUR * 2
페이팔 수수료 : 7$
배송료 : 15$
관세 + 배대지 수수료 : 53,950원
… 참 금액도 글로벌하게 나갔다 .. 전체 대략 원화로 59만원 즈음 되는거 같다… 후아…